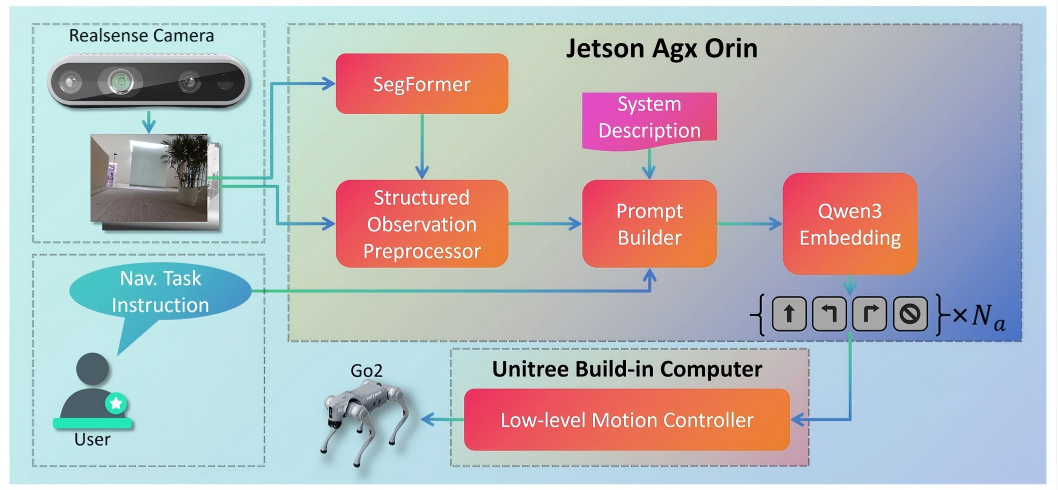
Method Overview
RGB-D observations are converted into structured textual descriptions with multi-resolution grids encoding depth, semantic, and color information, forming a pure language prompt for a pre-trained LLM.
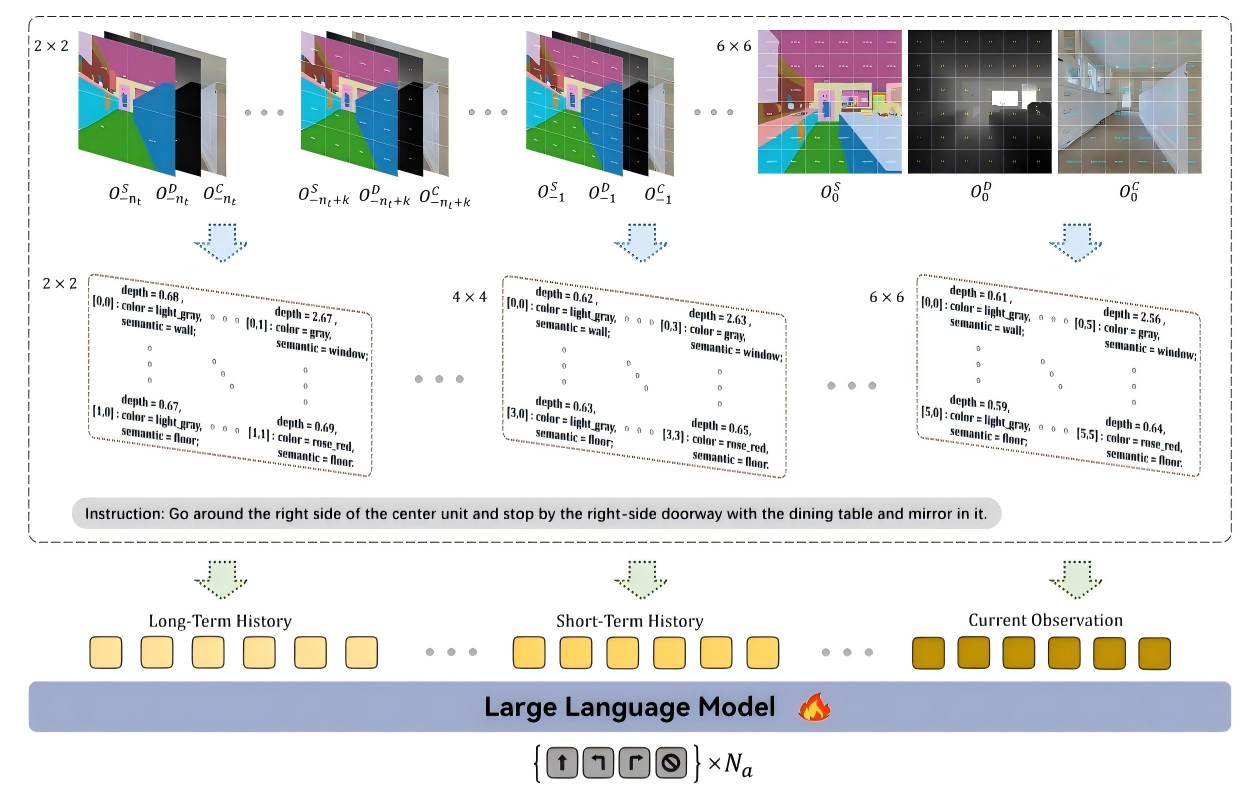
Fig. 1. Pipeline of SOL-Nav. RGB-D observations are converted into structured textual descriptions with 2×2 / 4×4 / 6×6 multi-resolution grids (long/short-term history, current observation) encoding depth, semantic, and color information. The structured observation sequence, navigation instruction, and system description form a pure language prompt for action prediction.

Fig. 2. Structured Observation Language Prompt for LLM. The prompt integrates system description, structured observations at multiple time steps, and task instruction to guide the language model for action prediction.