Method Overview
A dual-stream encoder with multi-scale fusion and large-kernel bridge for efficient RGB-LiDAR road segmentation.
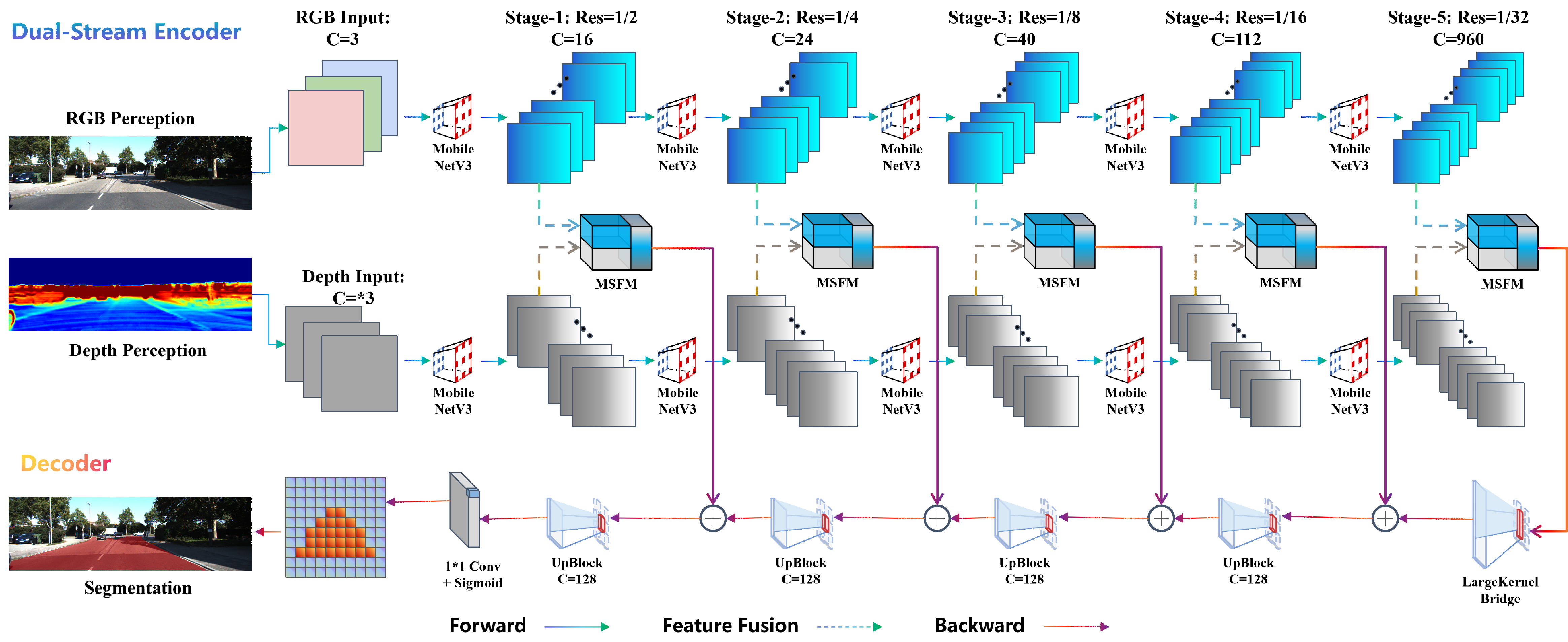
Fig. 1. Overall Architecture of LiteViLNet. The network consists of a dual-stream lightweight encoder (MobileNetV3 for RGB and depth), Multi-Scale Feature Fusion Modules (MSFM) at each stage, a large-kernel-bridge module, and a decoder with deep supervision producing the segmentation mask.

Fig. 2. ADI Generation Pipeline. Raw 3D LiDAR point cloud is projected onto the image plane via intrinsic/extrinsic calibration, then converted into a 2D Altitude Difference Image (ADI) using a 7×7 weighted height difference computation, encoding local height differences between ground plane and obstacles.
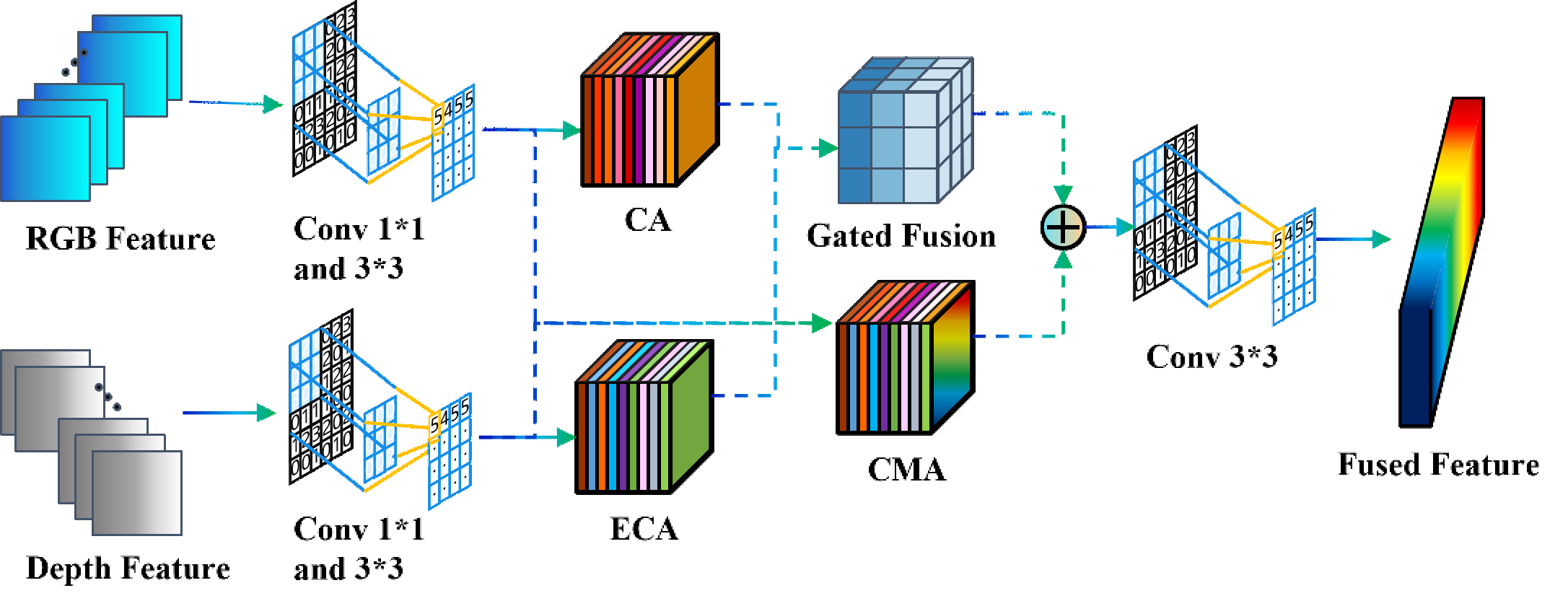
Fig. 3. Architecture of the Multi-Scale Feature Fusion Module (MSFM). It sequentially performs channel compression, intra-modal enhancement (ECA), coordinate attention, bidirectional cross-modal attention, and adaptive gated fusion to integrate complementary RGB texture and LiDAR geometric information at each feature scale.


