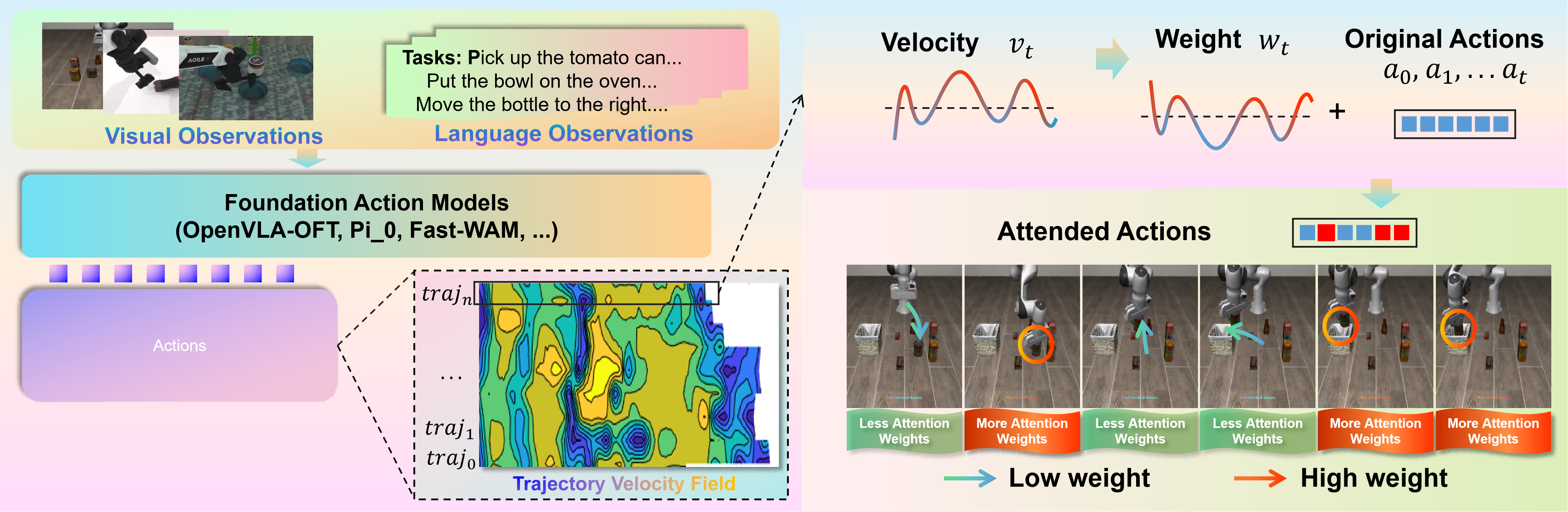
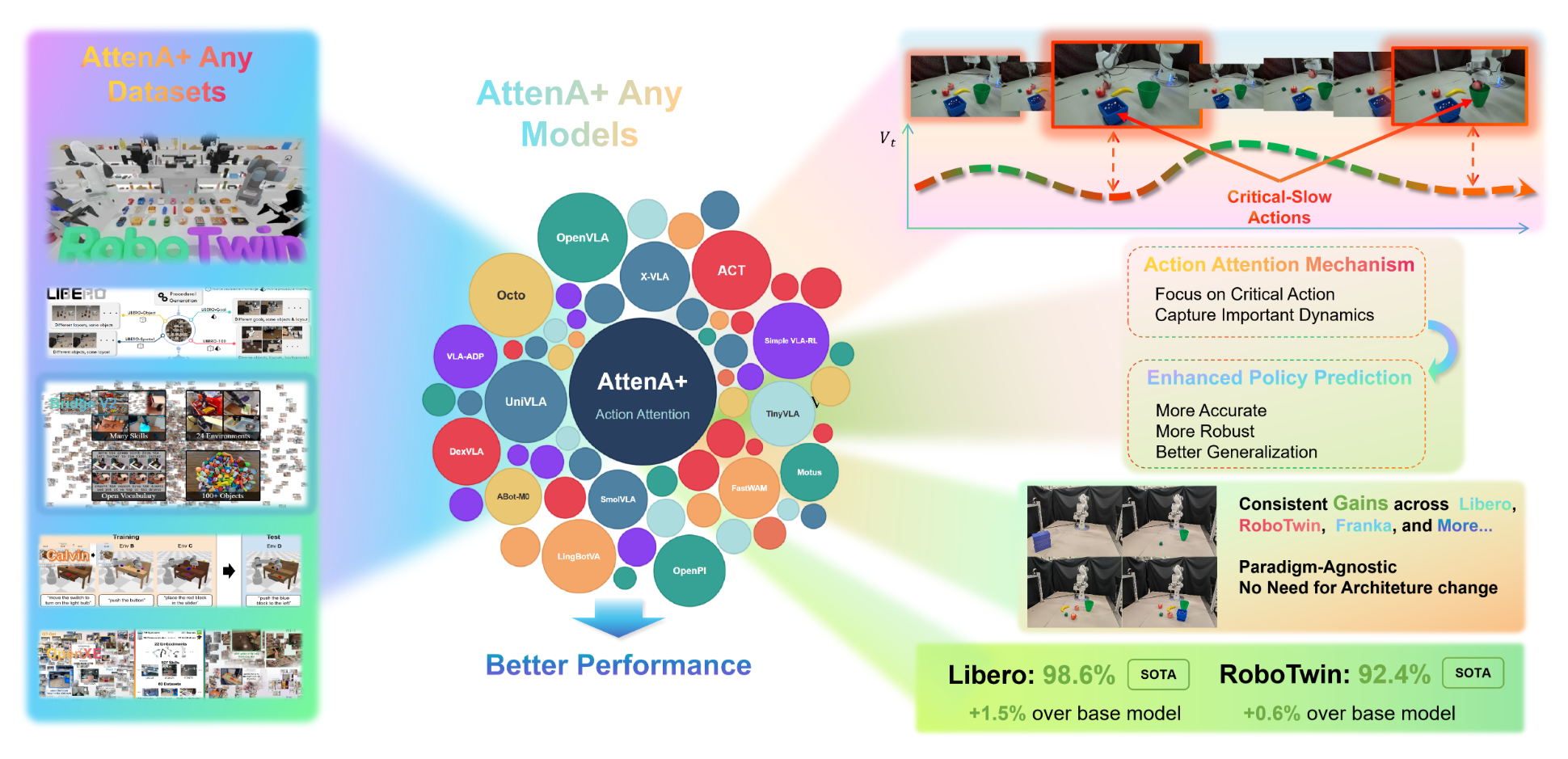
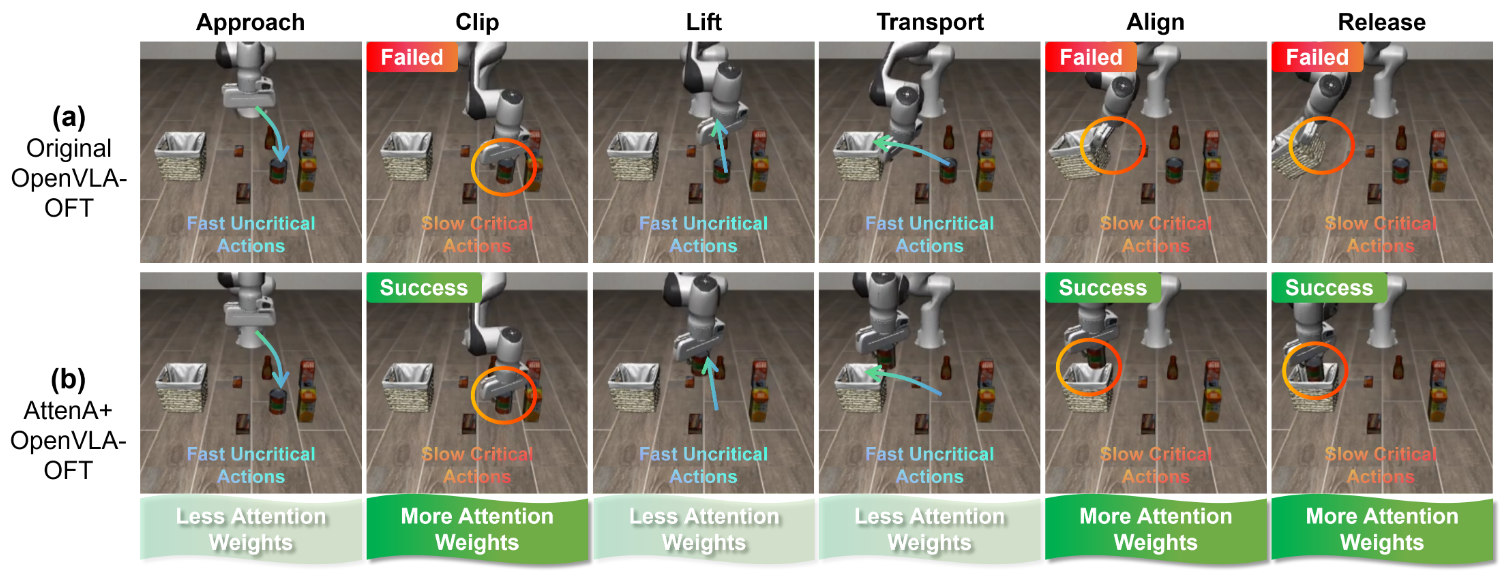
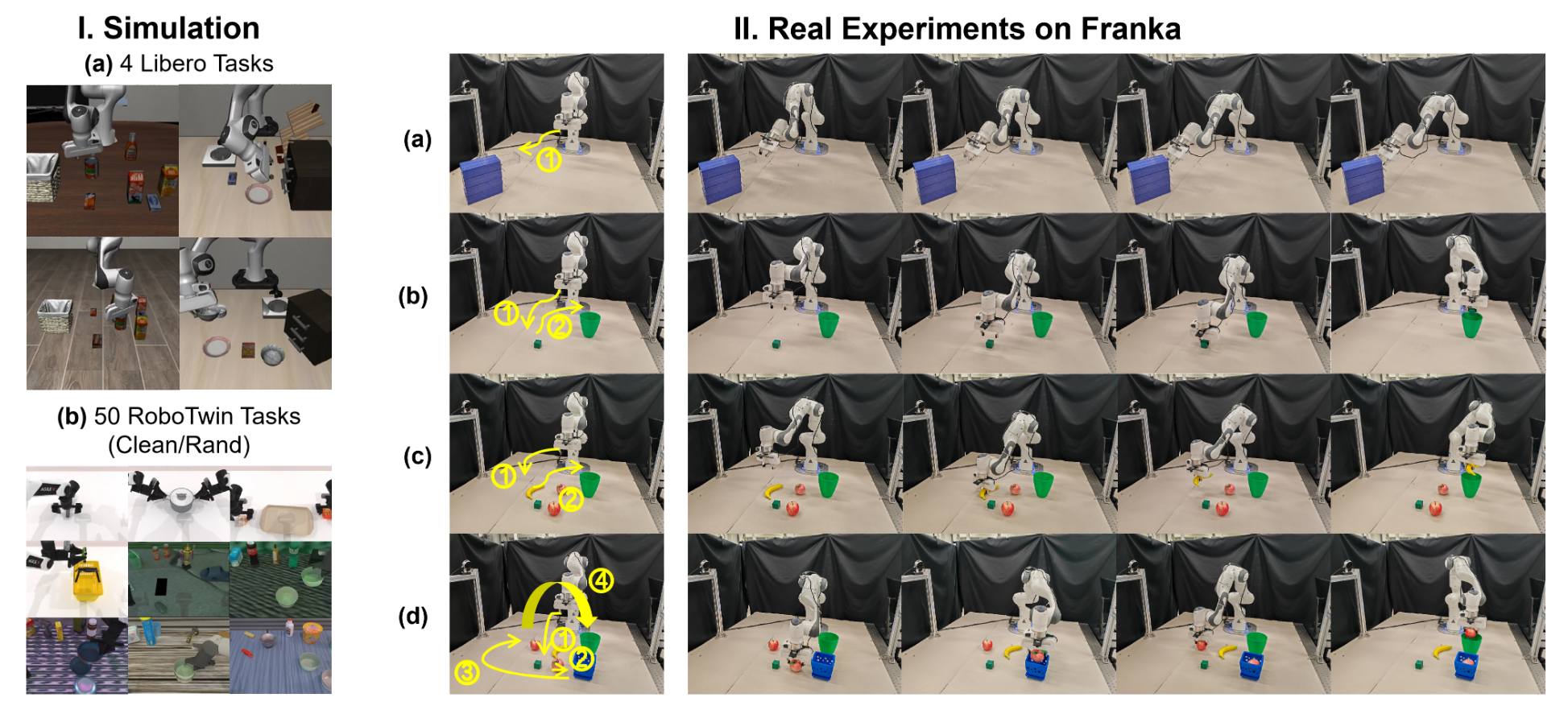
Motivation
Action Inequality in Robot Trajectories
Not all actions are created equal. Velocity field analysis reveals that slow, precision-demanding steps (grasp, align, place) are far more critical than fast transitions.

Figure 2: Velocity fields reveal inherent action inequality. Rapid motions are often redundant transitions, while slow-motion phases dominate task success or failure.